Background in applied mathematics. I build backend systems, data tooling
and internal infrastructure — the kind of work where getting the model
right matters more than the UI.
Best fit
Backend and data roles, research software, internal tools and AI tooling
Adelaide or remote — particularly Python or TypeScript systems, data
validation, APIs, research software and AI-tooling infrastructure.
Places where correctness is the actual requirement, not a nice-to-have.
Self-directed engineering projects, documented so employers can inspect
architecture, tests, trade-offs and limitations. Everything here is
real and linked — nothing hypothetical.
A production-grade quantitative runtime I designed and built for
research, simulation and live execution. One strategy contract spans
backtest, paper, sandbox and live — shared state, attribution, central
risk, routing and venue behaviour all stay explicit across the boundary.
In engineering terms: event-driven Python, typed
strategy contracts, isolated venue adapters, a central risk ledger,
full position attribution and a feed benchmark of 642k events/second.
The test suite runs in CI.
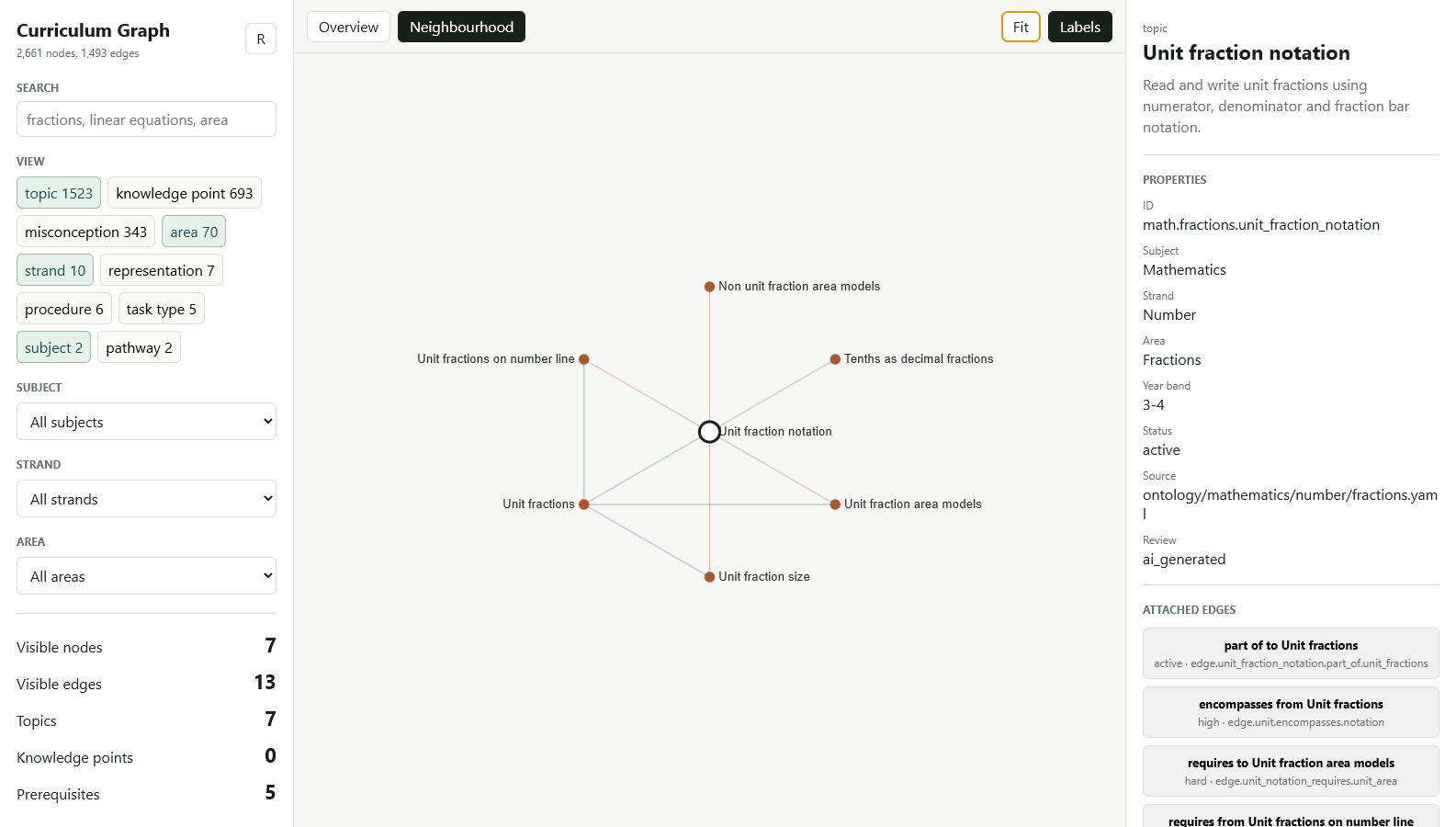
A curriculum knowledge graph with more than 2,500 nodes. Schema
validation, search, auditable patch logs, MCP access, JSON/JSON-LD
exports and a local browser explorer.
Demonstrates: schema design, graph queries,
deterministic exports, and AI-assisted editing with human review
and auditable patch logs — the kind of discipline that makes
LLM-assisted authoring trustworthy rather than just fast.
TypeScript
YAML
Knowledge graphs
MCP
Full-stack research softwareTwo paper-scale projects
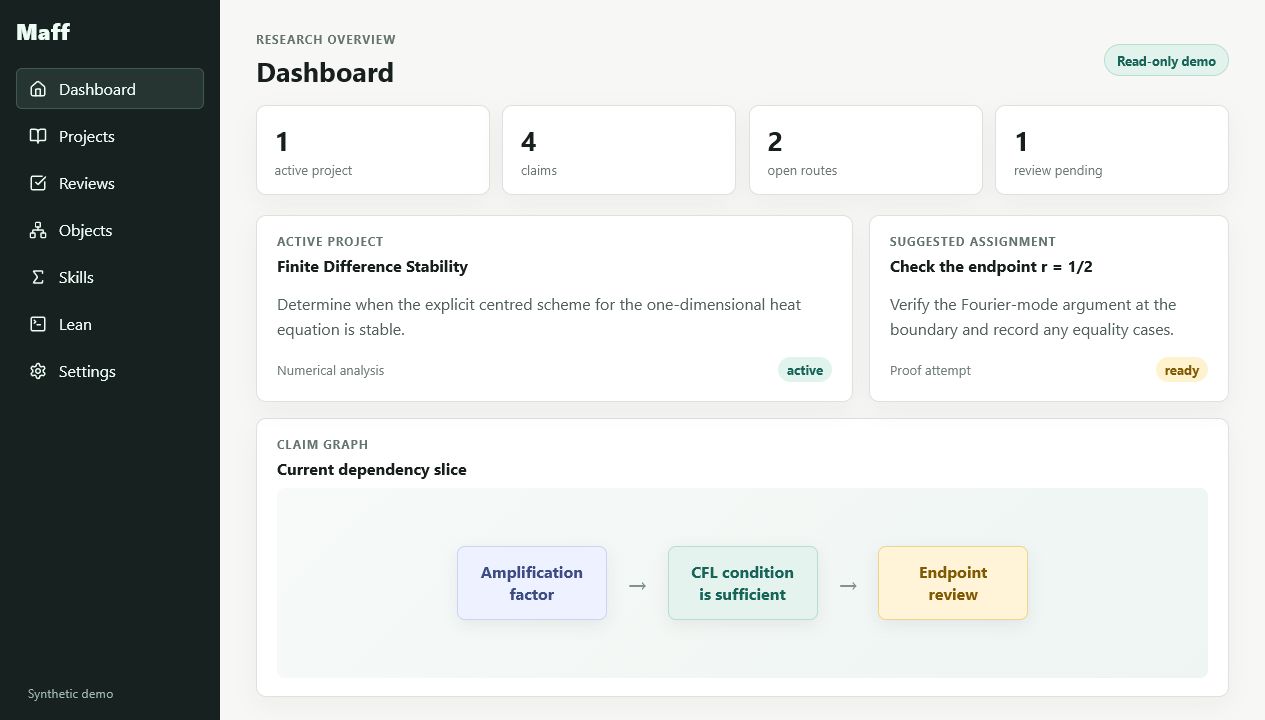
A TypeScript, React and PostgreSQL workspace for sustained
mathematical research. Notes, claim graphs, review queues, MCP
access and Lean integration — all in one self-hosted system I
actually use.
In workplace terms: authenticated React UI,
TypeScript REST API, PostgreSQL index and cache, audit logs,
Docker deployment and a formal-methods worker. Built as a real
internal platform, not a demo.
Reverse-engineered Signal Android's newer folder-based backup format
to selectively export conversations and media to HTML, Markdown and
JSON. Tests use synthetic fixtures; no personal data published.
A Model Context Protocol server that turns trusted LaTeX input into
cached PDFs and exposes reusable templates and snippets. Packaged
for repeatable local deployment with Docker.
A Go/FUSE filesystem that presents persistent alternate directory
layouts without moving or modifying source data. Immutable source
access, state backups, extended attributes, unit tests and Linux CI.
Go
FUSE
Linux
Background
Mathematical research, carried into systems engineering.
I came to software through maths research and university teaching, not
a bootcamp or conventional web-dev path. That shapes how I work — I tend
to think about the data model before the API, and I'd rather document
limitations honestly than paper over them.
Since 2022 I've been building independently: a quantitative trading
runtime, a curriculum knowledge graph, a research workspace, filesystem
tooling. These are real systems I use — not portfolio pieces assembled
for an interview.
My engagement with machine learning goes back to a graduate summer school
in 2017 and deep-learning coursework in 2019, well before the current
wave of LLM tooling. I'm most useful where the problem is underspecified,
the data model has real structure, and the finished system needs to stay
understandable.
Research runtimes, MCP servers, typed tool interfaces, human-review workflows, audit trails and deterministic processing around LLMs.
Production habitsAutomated testsDockerCIStructured logsSecurity notesAudit trailsExplicit limitations
Contact
Working on something complicated that needs to stay understandable?
Based in Adelaide, open to remote. I'm looking for backend, data or
research software roles — particularly where the domain is messy and
someone needs to actually understand the system they're building.
Email is fastest; I usually reply same day.